9号通宵大战,总算大致赶完了一篇报告。这个通宵让我创下了42小时不睡觉的记录,其惨烈程度可想而知。这篇 报告的主题是针对人口抽样调查数据进行分析,得出地区人口素质的一些描述性结论。其实我的相当大一部分时间都花在了处理数据上面,因为数据比较庞大,一共 有260万行、90个变量,数据文件大小在FoxPro存储格式下为424M,首先我要想办法将 FoxPro数据转化为一般常见的数据库格式,因此将之导出为dBase IV(*.dbf),这样SPSS就可以读了(当然也可以用R的RODBC包读), 从dBase IV转为SPSS格式(*.sav)之后文件大小变为约1.5G,但很容易就能找出减小数据文件大小的办法:将以文本形式(String)表示的数字转化 为数值型(Numeric)即可(其实这份数据中的大部分数值都是用文本形式保存的,除非以零开头,都可以直接转换为数值形式)——我并不了解真正的 SPSS存储形式,但我猜测对于字符数据,至少要比数值数据多两个引号吧。初步整理之后,文件大小能缩减到400多M,当然我是不会直接用SPSS来作分 析的,因为速度太慢,一个变量的频数统计就要花半分钟时间,我可没那么多时间和耐心去等。最终我采用的办法是将数据存为纯文本格式,具体来说是逗号分隔符 数据(*.csv),然后开始用R来作分析。到这里,数据的预处理仍然没有结束,我为了让分析做得更快,又采取了一个策略:将每一列变量都单独存为一个数 据文件。要达到这样的目的,当然要首先把每一列变量提取出来,那么怎样依次提取变量呢?方法很简单,用SQL的select语句即可。文本文件当然也可以 当作数据库来处理,因为Windows一般会有文本文件的ODBC Driver,利用R的RODBC包结合SQL的select语句,变量就可以顺利被选择出来了。
以下是一个R程序示例:
# 生成一个随机的Poisson矩阵
> x = apply(matrix(rpois(1e+05, 5), ncol = 10), 2, as.integer)
> colnames(x) = LETTERS[1:10] 将列命名为A-J的十个字母
> print(x[1:10, ]) 这是数据的形式
A B C D E F G H I J
[1,] 2 2 9 3 5 5 3 8 3 5
[2,] 4 5 1 2 6 3 6 6 4 7
[3,] 7 4 4 3 2 3 5 1 8 5
[4,] 5 7 2 5 6 7 6 7 4 3
[5,] 10 3 5 4 6 7 5 5 1 5
[6,] 1 6 8 3 6 2 4 7 5 3
[7,] 7 5 3 4 2 4 2 4 4 7
[8,] 4 6 4 1 4 3 4 1 2 3
[9,] 2 0 4 9 6 6 7 3 3 10
[10,] 2 2 8 2 5 9 4 5 4 8
> f = c("c:/x.csv", "c:/x.RData", "c:/y.RData")
> write.csv(x, file = f[1], row.names = F) csv格式文件
> save(x, file = f[2]) 二进制文件
> y = x
> save(y, file = f[3], ascii = T) ASCII文件
> print(file.info(f)[, 1:3]) 看看三种文件的大小对比
size isdir mode
c:/x.csv 213189 FALSE 666
c:/x.RData 64389 FALSE 666
c:/y.RData 203336 FALSE 666
> require(RODBC) 加载RODBC包
# 注意,"Text Files"只是我自己命名的一个数据库连接,
# 请按照图1、图2的步骤建立文本数据库驱动的连接
# 这里也可以将odbcConnect()的参数设为空字符串""
# 这样系统会自动弹出选择ODBC连接的对话框
> channel = odbcConnect("Text Files")
> print(sqlColumns(channel, "x.csv")[, c(1, 3, 4, 6)])
TABLE_CAT TABLE_NAME COLUMN_NAME TYPE_NAME
1 C:\ x.csv A INTEGER
2 C:\ x.csv B INTEGER
3 C:\ x.csv C INTEGER
4 C:\ x.csv D INTEGER
5 C:\ x.csv E INTEGER
6 C:\ x.csv F INTEGER
7 C:\ x.csv G INTEGER
8 C:\ x.csv H INTEGER
9 C:\ x.csv I INTEGER
10 C:\ x.csv J INTEGER
# 要依次保存所有的列,只需要把这里的SQL语句放在循环中即可
# 比如paste("select", i, "from x.csv", collapse = " ")
# 让i在LETTERS[1:10]中循环
> sqlQuery(channel, "select A,B from x.csv")[1:10, ]
A B
1 2 2
2 4 5
3 7 4
4 5 7
5 10 3
6 1 6
7 7 5
8 4 6
9 2 0
10 2 2
> odbcClose(channel) 关闭ODBC连接
> file.remove(f) 删掉前面生成的三个文件
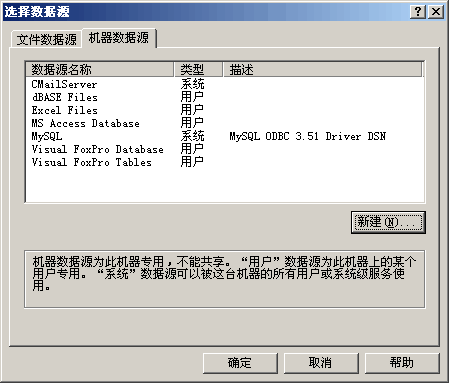
图1:新建数据源(控制面板–>管理工具–>数据源 (ODBC);添加)
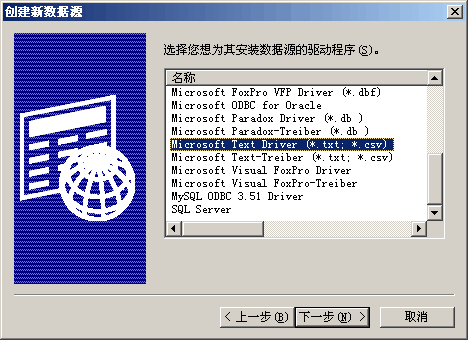
图2:Microsoft Text Driver
用R处理完数据之后,预处理过程才算真正结束了,这里要特别提一句的是,由于R的save()函数默认采用二进制存储方式(而不是直接存储ASCII字符),数据的大小便可以被大幅度压缩,最后以二进制数据形式存储的这90个变量大小之和才50M左右——数据大小被压缩到原来的1/10。
这次采取的另一个节省时间策略就是上一篇日志里 提到的远程桌面连接;我自己这台电脑跑起来比较慢,于是我把这些数据处理工作都交给了办公室的另一台电脑,在那里执行我的R语句,然后回到自己的电脑同时 做别的工作,等那边的计算结束之后再把结果复制回来就可以了。由于R的计算都是在内存(RAM)中进行,大家都知道读写内存的速度比读写硬盘或其它存储的 速度要快很多倍,R的计算速度尤其是在这种大型数据的情况下就显得极其快,频数统计(table()函数)往往都是半秒不到就计算出来了。 当然,这世上不存在绝对好或者绝对差的东西,读写内存必然对内存有一定的要求(主要是内存大小),比如当数据很庞大的时候,Windows下就很难把数据 一口气读进来。我前面将每一列变量单独存为数据文件的做法其实也是回避这个缺点,因为我的分析并不需要每次都用到所有的变量,而加载一列数据的时间也是很短的,用谁就加载谁。